TPC && PPC && Reactor && proactor
[TOC]
高性能架构设计主要集中在两点:
- 尽量提升单服务器的性能,将单服务器的性能发挥到极致
- 如果单服务器无法支撑性能,设计服务器集群方案
架构设计决定了系统性能的上限,实现细节决定了系统性能的下限
单服务器高性能的关键之一就是服务器采取的并发模型,并发模型设计的两个关键点:
- 服务器如何管理连接
- 服务器如何处理请求
以上两个设计点最终都和操作系统的 I/O 模型及进程模型相关
- I/O 模型:阻塞、非阻塞、同步、异步
- 进程模型:单进程、多进程、多线程
PPC
Process Per Connection -> 每次有新的连接就新建一个进程去专门处理这个连接的请求
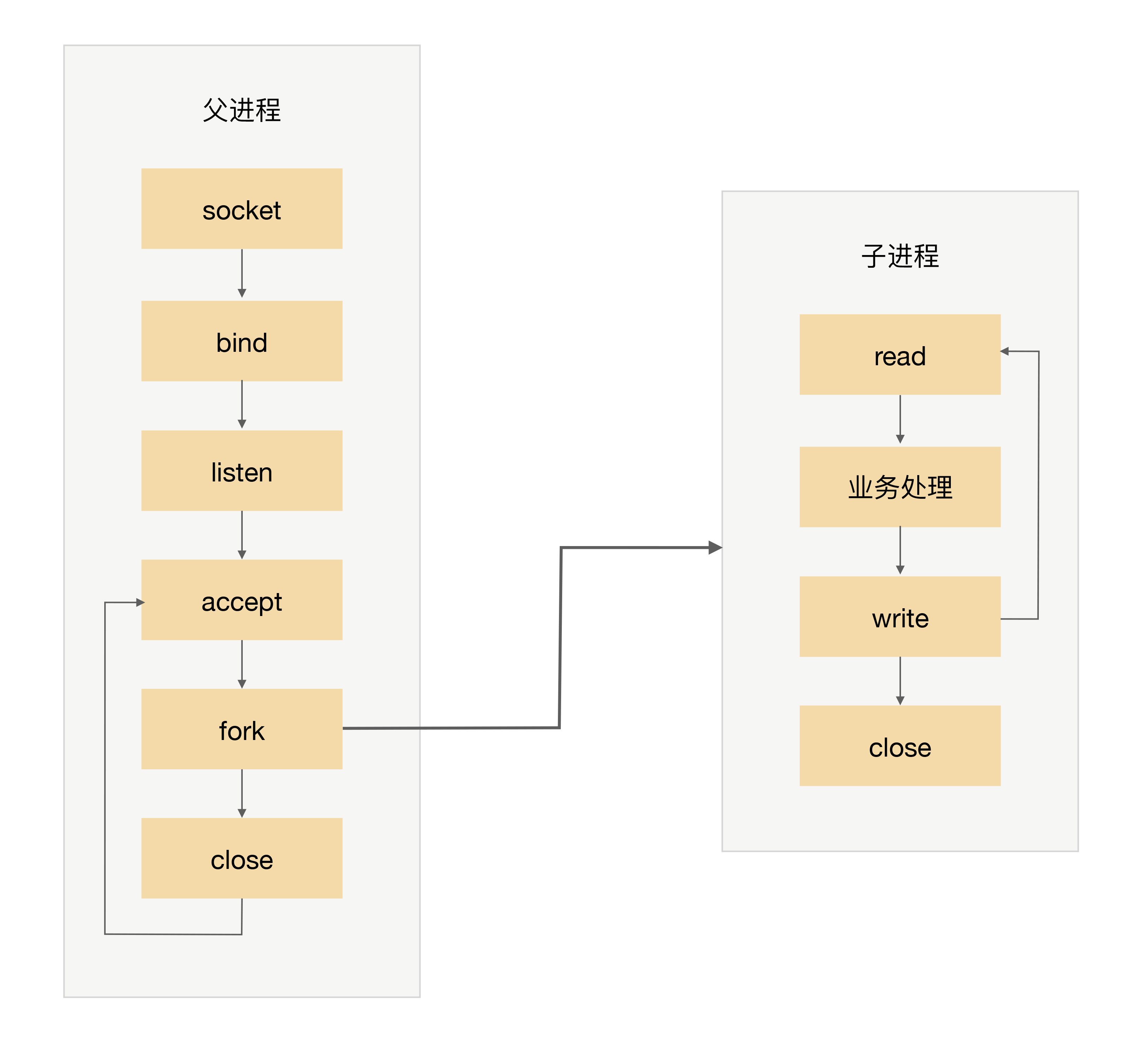
- 父进程接受连接(accept)
- 父进程 fork 子进程(fork)
- 子进程处理连接的读写请求(read\业务处理\write)
- 子进程关闭连接(close)
在当父进程 fork 子进程后,直接调用了 close,实际上只是将连接的文件描述符引用计数减一,真正的关闭连接是等子进程也调用 close 后,连接对应的文件描述符的引用计数变为 0 后,操作系统才会真正关闭连接。
PPC 模式实现简单,比较适合服务器的连接数没那么多的情况,例如数据库服务器。当服务器的访问量增加后,这种模式的弊端主要体现在:
- fork 代价高:在操作系统的角度,fork 一个进程的代价较高,需要分配很多内核资源,需要将内存映像从父进程复制到子进程。即使现在的操作系统在复制内存映像时用到了 Copy on Write 技术,但是创建一个进程的代价还是很大的
- 父子进程通信复杂:父子之间需要通过 IPC (Interprocess Communication)之类的进程通信方案。
- 支持的并发连接数量有限:如果每个连接存活时间比较长,而且新的连接又源源不断的进来,则进程数量会越来越多,操作系统进程调度和切换的频率也会越来越高,系统的压力也会越来越大。
prefork
由于 fork 进程代价较高,用户访问时可能会感觉比较慢,prefork 模式的出现就是为了解决这个问题。
prefork 就是提前创建进程(pre-fork)。系统在启动的时候就预先创建好进程,然后才开始接受用户的请求,当有新的连接进来的时候,就可以省去 fork 进程的操作,让用户访问更快、体验更好。
TPC
TPC 是 Thread Per Connection 的缩写,其含义是指每次有新的连接就新建一个线程就专门处理这个连接的请求。优点如下:
- 线程相较于进程而言,更加轻量级;
- 多线程是共享内存空间的,线程通信比进程更加简单;
TPC 实际上是解决或者弱化了 PPC fork 代价高的问题和父子进程通信复杂的问题;
TPC 虽然解决了 fork 代价高和进程通信复杂的问题,但是也引入了新的问题:
- 当遇到高并发问题时(每秒上万连接),还是有性能问题;
- 无须进程间通信,但是线程间的互斥和共享引入了复杂度,会造成死锁问题;
- 多线程会出现互相影响的情况,当某个线程出现异常时,可能导致整个进程退出(内存越界)
TPC 还存在 CPU 线程调度和切换代价的问题。因此 TPC 方案本质上和 PPC 方案基本类似,在并发几百的连接下,反而更多的是采用 PPC 的方案,因为 PPC 方案不会有死锁的风险,也不会多进程互相影响,稳定性更高。
prethread
TPC 模式中,当连接进来时才创建新的线程来处理连接请求,虽然创建线程比创建进程要更加轻量级,但还是有一定的代价,而 prethread 模式就是为了解决这个问题。
和 prefork 类似,prethread 模式就会预先创建线程,然后才开始接受用户的请求,当有新的连接进来的时候,就可以省去创建线程的操作,让用户感觉更快、体验更好。
Apache 服务器的 MPM worker 本质上就是一种 prethread 方案。Apache 服务器会首先创建多个进程,每个进程里面再创建多个线程,这样做主要是为了考虑稳定性,即:即使某个子进程里面的某个线程异常导致整个子进程退出,还会有其他子进程继续提供服务,不会导致整个服务器全部挂掉。
PPC && TPC 应用场景分析
什么样的系统适用于上述的模式呢?
首先 PPC 和 TPC 能够支持的最大连接数差不多,都是几百个
- 海量连接海量请求:秒杀、双十一,上述的模式都不适合;
- 常量连接(几十上百)海量请求:中间件、数据库,redis 等,适合;
- 海量连接常量请求:门户网站;不适合
- 常量连接常量请求:内部管理系统,上述的模式比较适合
更多的情况时采用二者结合的系统,例如上述介绍的 MPM worker,采用多进程下的多线程,保持服务的高可用。
Reactor
reactor 的由来:
对于 PPC && TPC 而言,其高并发场景是不适用的
PPC 模式最主要的问题就是每个连接都要创建进程(或者线程),连接结束后进程就销毁了,这样其实造成了巨大的浪费。为了解决这个问题,使用进程池,将连接分配给进程,一个进程可以处理多个连接的业务。
引入资源池的处理方式后,会引出一个新的问题:进程如何才能高效地处理多个连接的业务?
当一个连接一个进程时,进程采用 “read -> 业务处理 -> write”的处理流程,此时会导致大量进程会阻塞在 read 上,这样是无法做到高性能的。
解决这个问题的最简单的方式是将 read 操作改为非阻塞,然后进程不断地轮询多个连接。
这种方式能够解决阻塞的问题,但是在遇到一个进程处理几千上万的连接时,轮询的效率是非常低的。
为了能够更好地解决上述问题,只有当连接上有数据的时候,进程才会去处理,这就是 I/O 多路复用技术的来源
IO 多路复用技术有两个关键实现点:
- 当多条连接共用一个阻塞对象后,进程只需要在一个阻塞对象上等待,而无须轮询所有连接,常见的方式有:select、epoll、kqueue 等
- 当某条连接有新的数据可以处理时,操作系统会通知进程,进程从阻塞状态返回,开始进行业务处理
IO 多路复用结合线程池,完美地解决了 PPC 和 TPC 的问题。这也就是 Reactor模式,可以通俗的理解为来了一个事件我就有相应的反应。
Reactor 模式也叫 Dispatcher 模式,更加贴近模式本身的含义,即 I/O 多路复用统一监听,收到事件后分配给某个进程。
Reactor 模式的核心组成部分包括 Reactor 和处理资源池,其中 Reactor 负责监听和分配事件,处理资源池负责处理事件。
结合不同的业务场景,Reactor 模式的具体实现方案灵活多变,主要体现在:
- Reactor 的数量可以变化:可以时一个 Reactor, 也可以是多个 Reactor。
- 资源池的数量可以变化,可以是单个进程,也可以是多个进程。
最终 Reactor 模式有三种典型的实现方案:
- 单 Reactor 单进程 / 线程。
- 单 Reactor 多线程。
- 多 Reactor 多进程 / 线程。
单 Reactor 单进程 / 线程
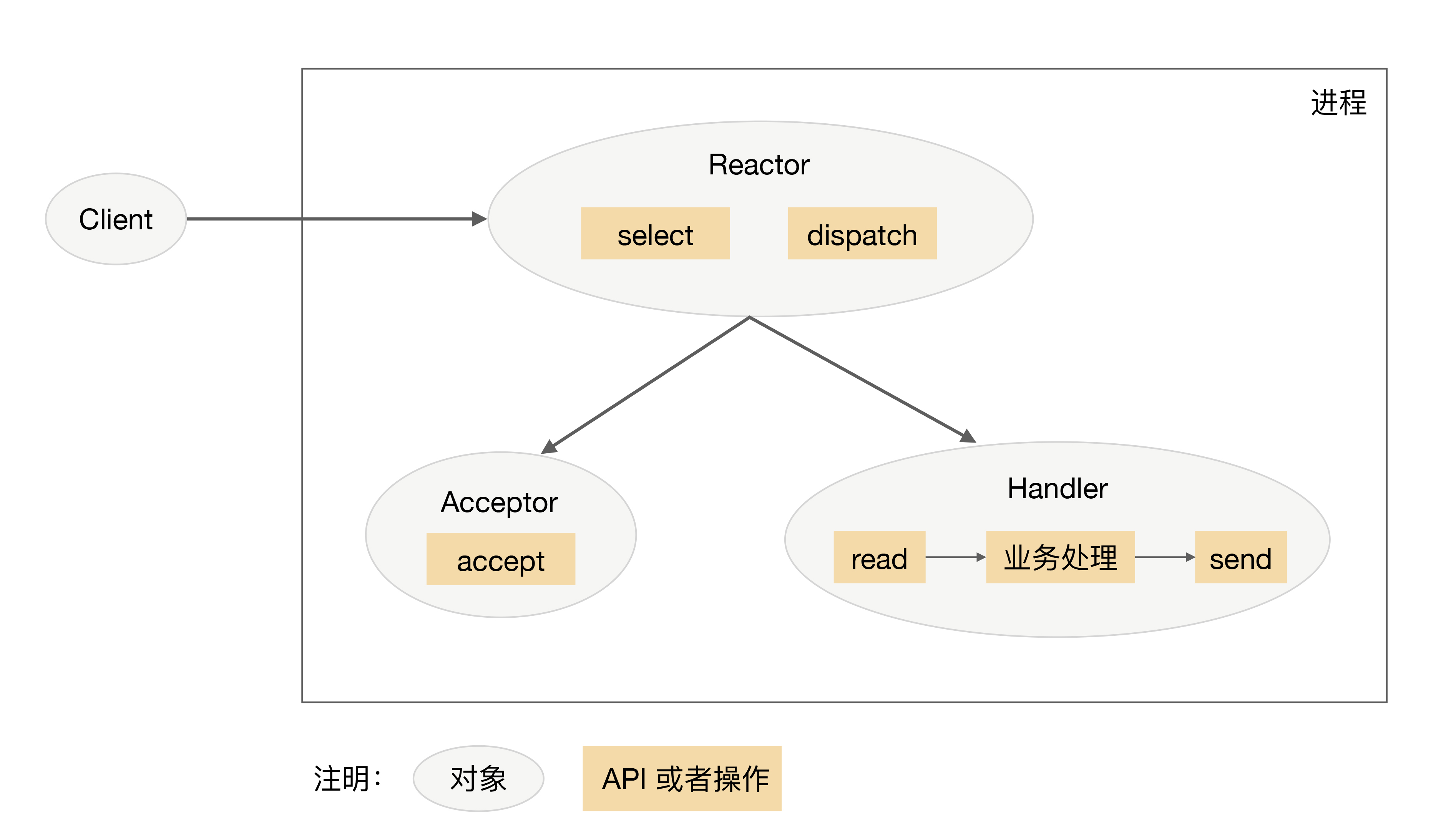
流程:
- Reactor 通过 select 监控连接事件,收到事件后通过 dispatch 进行分发。
- 如果是建立连接的事件,则由 Acceptor 处理, Acceptor 通过 accept 接受连接,并创建一个 Handler 来处理连接后续的各种事件。
- 若不是连接事件,则 Reactor 会调用连接对应的 Handler 来进行响应。
- Handler 会完成 read -> 业务处理 -> send 的完整业务流程。
单 Reactor 单进程的模式优点如下:
- 无进程间通信,没有竞争,全部都在一个进程中完成
缺点也非常明显,具体表现有:
- 只有一个进程,无法发挥多核 CPU 的性能;
- Handler 在处理某个连接上的业务时,整个进程无法处理其他连接的事件,很容易导致性能瓶颈。
因此,单 Reactor 单进程的方案在实践中应用的场景不多,只适用于业务处理非常快速的场景,目前比较著名的开源软件中使用单 Reactor 单进程的是 Redis。
单 Reactor 多线程
针对 Handler 的性能瓶颈,引入多进程 / 多线程是显而易见的,这就产生了第二个方案:单 Reactor 多线程。
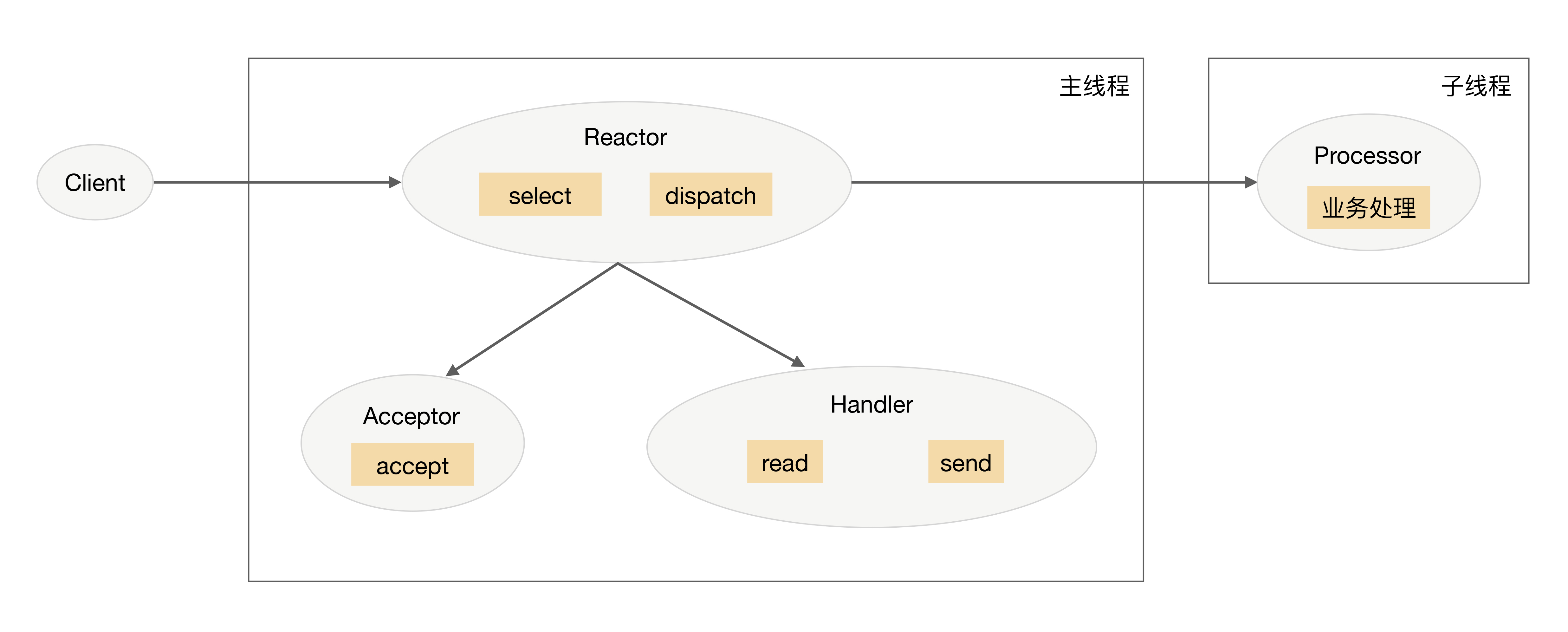
流程为:
- 主进程中,Reactor 对象通过 select 监控连接事件,收到事件后通过 dispatch 进行分发;
- 如果是连接建立的事件,则由 Acceptor 处理,Acceptor 通过 accept 接受连接,并创建一个 Handler 来处理连接后续的各种事件;
- Handler 只负责响应事件,不进行业务处理;Handler 通过 read 读取到数据后,会发给 Processor 进行业务处理;
- Processor 会在独立的子线程中完成真正的业务处理, 然后将响应结果发送给主进程的 Handler 处理;Handler 收到响应后通过 send 将响应结果返回给 client;
单 Reactor 多线程的方案能够充分利用多核多 CPU 的处理能力,但同时也存在下面的问题:
- 多线程数据共享和访问比较复杂。
- Reactor 承担所有事件的监听和响应,只在主线程中运行,瞬间高并发会成为性能瓶颈。
多 Reactor 多进程 / 线程
为了解决单 Reactor 多线程中 单 Reactor 瞬间高并发的性能瓶颈,最直接的方式就是采用多 Reactor 多进程监听;
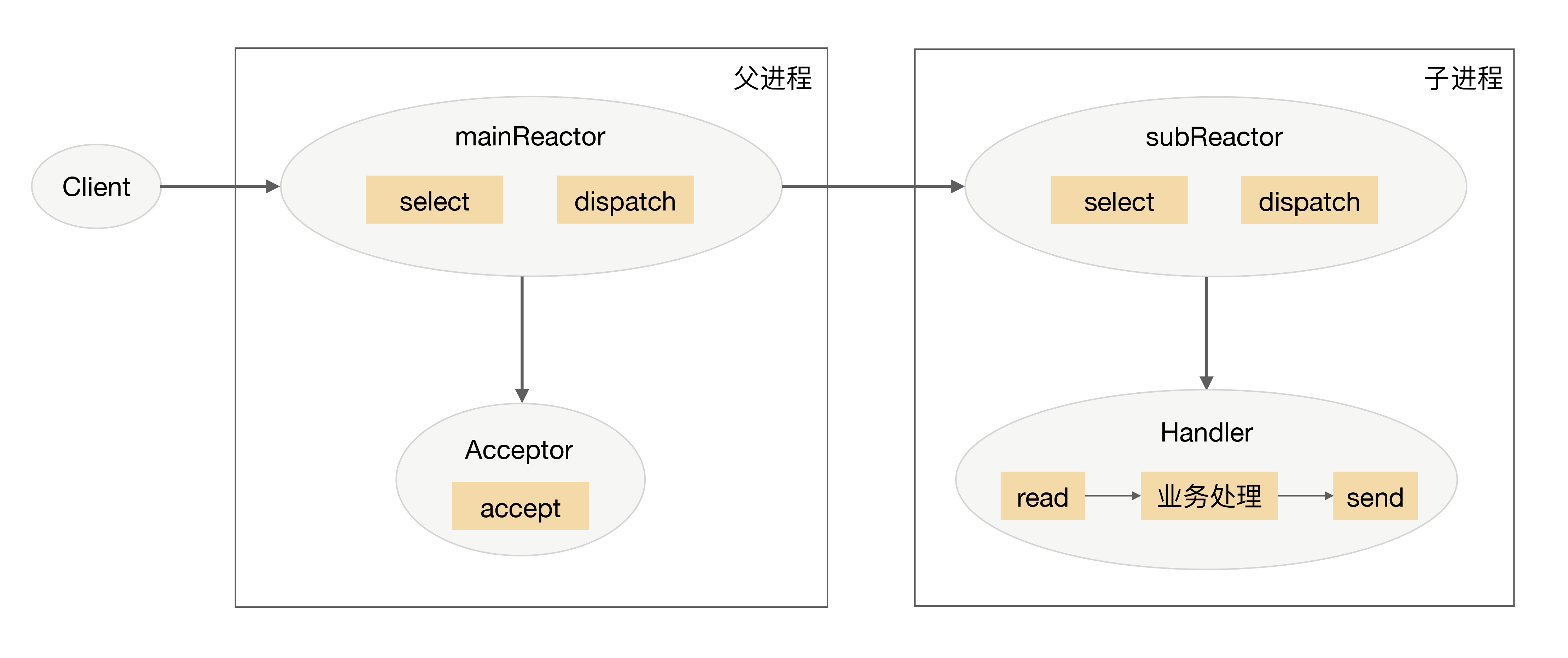
- 父进程中 mainReactor 对象通过 select 监听连接建立事件,收到事件后通过 Acceptor 接收,将新的连接分配给某个子进程。
- 子进程的 subReator 将 mainReator 分配的连接加入连接队列进行监听,并创建一个 Handler 用于处理连接的各种事件。
- 当有新的事件发生时,subReactor 会调用连接对应的 Handler 来进行响应。
- Handler 完成 read -> 业务处理 -> send 的完整业务流程。
上述方案在实现时相较于 单 Reactor 要简单:
- 父子进程的职责非常明确,父进程只负责接收新连接,子进程负责完成后续的业务处理
- 父进程和子进程的交互很简单,父进程只需要把新连接传给子进程,子进程无须返回数据。
- 子进程之间是互相独立的,无须同步共享之类的处理(仅限于网络模型的 select\read\send)
Nginx 采用的是多 Reactor 多进程的模式;但是方案与标准的多 Reactor 多进程有差异。
Proactor
Reactor 是非阻塞同步网络模型,因为真正的 read 和 send 操作都需要用户进程同步操作。
若将 I/O 操作改为异步就能够进一步提升性能,这就是异步网络模型 Proactor。
Reactor 可以理解为来了事件,我通知你,你来处理,而 proactor 可以理解为来了事件我来处理,处理完了我通知你
这里的我就是操作系统内核,事件就是有新连接、有数据可读、有数据可写这些 I/O 事件,你就是我们的程序代码。

流程:
Proactor Initiator 负责创建 Proactor 和 Handler,并将 Proactor 和 Handler 都通过 Asynchronous Operation Processor 注册到内核。
Asynchronous Operation Processor 负责处理注册请求,并完成 I/O 操作。
Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor。
Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理。
Handler 完成业务处理,Handler 也可以注册新的 Handler 到内核进程。
总结
关于 IO 操作一般分为两个阶段:
- 数据准备(读到内核缓存)
- 将数据从内核读到用户空间
一般而言 1 花费的时间远远大于 2。1 上阻塞 2 上也阻塞的称为同步阻塞。
1 上非阻塞 2 上也阻塞的称为同步非阻塞 IO,这讲的就是 Reactor 这种模型
1 上非阻塞 2 上非阻塞的称为异步非阻塞,这就是 Proactor
Reactor与Proactor能不能这样打个比方: 1、假如我们去饭店点餐,饭店人很多,如果我们付了钱后站在收银台等着饭端上来我们才离开,这就成了同步阻塞了。 2、如果我们付了钱后给你一个号就可以离开,饭好了老板会叫号,你过来取。这就是Reactor模型。 3、如果我们付了钱后给我一个号就可以坐到坐位上该干啥干啥,饭好了老板会把饭端上来送给你。这就是Proactor模型了。