如何设计一个可以应对各种异常情况的工业级散列表,来避免在散列冲突的情况下,散列表性能的急剧下降,并且能抵抗散列碰撞攻击?
在了解到的 「 散列表 」中,我们了解散列表的查询效率并不能笼统的说成 O(1),其依赖三个部分:
- 散列函数
- 装载因子
- 散列冲突
散列函数
如何设计一个又好又快的散列表
散列函数的设计不能太复杂,过于复杂的散列函数,势必会消耗很多计算时间,也就间接地影响到散列表的性能
散列函数生成的值要尽可能随机平均分布,最小化避免散列冲突
我理解为:简单且迅速且平均分布
常见的一些散列思想为:
- 数据分析法
- 直接寻址法
- 平方取中法
- 折叠法
- 随机数法
我这里介绍一下 数据分析法,比较好理解。
数据分析法
- 对于我们而言,在校园中,工作中,社会中,都会有自己的 ID 标识,这里用学号举例子:
- 2023011002
2023 级 大一 10 班 02 号
对于每一个学生的身份信息都可以使用这个 id 来存储:
1 | {"2023011002": {"name": "wang", "age": 1}} |
Hash(2023011002) == 011002 % 100000
- 还有就是 word 单词拼写检查功能。
对于词库的存储,其每个单词都可以通过 ASCII 码 进位相加,然后再和散列表的大小取余、取模,作为散列值。
1 | hash("nice")=(("n" - "a") * 26*26*26 + ("i" - "a")*26*26 + ("c" - "a")*26+ ("e"-"a")) / 123456 |
当然,这种方法都只是一种分析方法,捉襟见肘
装载因子
装载因子描述的是散列表中元素的个数大小情况,成正比。
对于动态散列表而言,数据集合是频繁变动的,我们无法准确的预估将要加入的数据个数,所以我们也无法事先申请一个足够大的散列表。这个时候动态扩容就变得很重要了
对于数组的扩容策略而言,只需要空间申请&&数据搬移即可,但是散列表的数据搬移就会显得比较复杂:当散列表的大小变化后,数据存储的位置也会发生变化,这是因为空间是新申请的,即使哈希值没有变化,但是空间地址已经发生了变化。
例如:原本的 21 的 index == 0,但是经过扩容后,index == 7
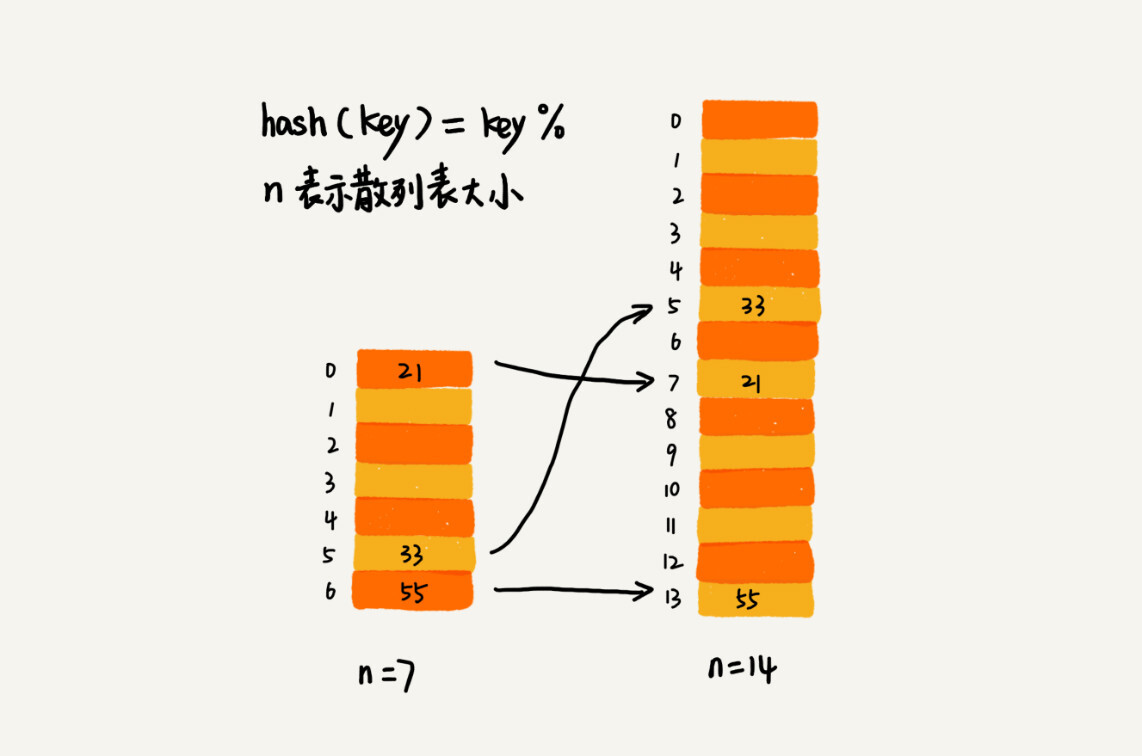
高效的扩容
装载因子阈值的设置要权衡时间、空间复杂度。
对于动态扩容而言,当采用单纯的设置阈值的方式进行扩容,会发生比较极端的情况。例如:当阈值设置为 1GB 时,那就需要对 1GB 的数据进行 hash ,然后进行数据搬移,此时就会比较耗时,如果涉及到用户操作,那么可能发生阻塞。
于是,采用分而治的思想,我们可以在每次插入的时候进行扩容,分批完成。当装载因子触及阈值时,我们只申请新空间,但是不将老的数据插入。当有新的数据插入的时候,我们将新数据插入到新申请的空间中,然后将老的数据搬移,经过多次插入操作后,就完成了动态搬移。
其实上述的思想就是渐进式 rehash,其本质是空间换时间。
渐进式 Rehash 这一实现的/类似的思想,本质是空间换时间。 1. Redis 的全局哈希表就是这么做的。具体可以看 https://time.geekbang.org/column/article/268253 2. 在 RocksDB 中也有体现。利用两个相同的内存空间 Memtable1 和 Memtable2,一个用来接收正在写入的数据,一个备着。当 Memtable1 写满了数据,再去刷盘,然后 Memtable2 来写入数据,这个是可以限流的。轮换着写入数据 -> 刷盘。具体的可以看 https://time.geekbang.org/column/article/298205 3. JVM 复制清除算法也是这么做的。
那么问题来了,查询操作如何执行呢?
为了兼容新、老数据,我们先从新的散列表中查找,如果没有找到,再去老的散列表中查找。
散列冲突
开放寻址法
开放寻址法可以有效地利用 CPU 缓存加快查询速度,这种方式实现的散列表比较好序列化。
当数据量较小,装载因子小的时候,适合采用开放寻址法。这也是 Java 中的 ThreadLocalMap 使用开放寻址法解决冲突的原因。
链表法
基于链表的散列冲突的处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,例如用红黑树代替链表。
链表法对内存的利用率比开放寻址法要高。
链表中的数据都是通过指针进行索引的,对于小对象而言,一个指针(4/8 bytes)可能会消耗更多,而对于大对象则可忽略。
实际上,链表法也是可以改造的,可以实现一个更加高效的散列表。那就是使用其他数据结构,例如跳表或着红黑树。
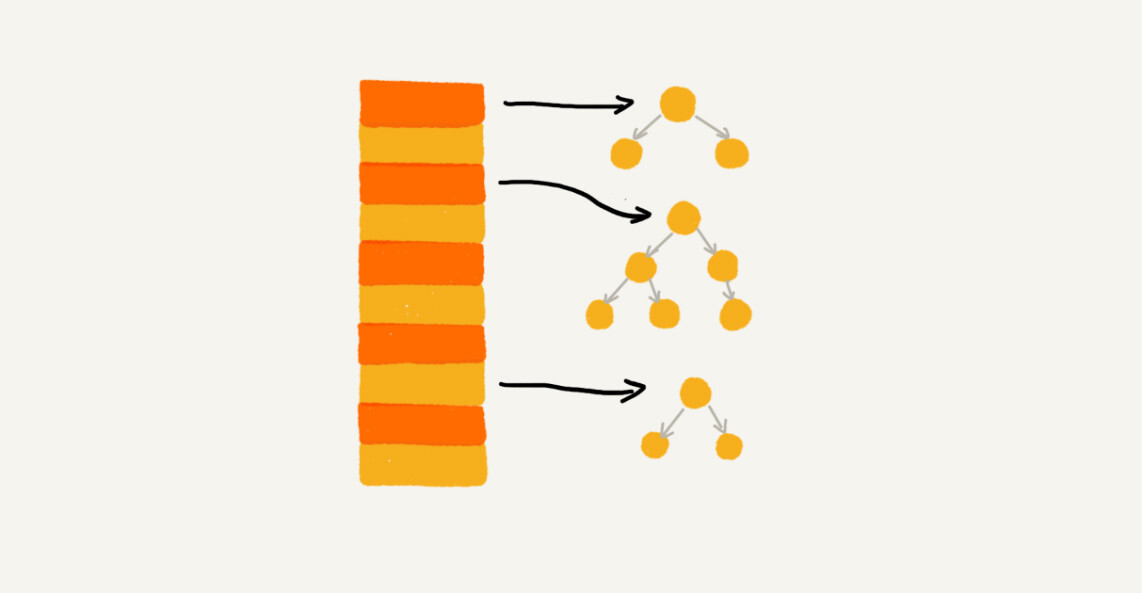
工业散列表
Java HashMap
1. 初始大小
Java HashMap 的默认初始大小是 16,可以配置修改;
2. 装载因子和动态扩容
最大的装载因子默认是 0.75,当 HashMap 中的元素个数超过 0.75 * capacity (capacity 表示散列表的容量)的时候,就会自动扩容,每次扩容都会扩容为原来的两倍大小。
3. 散列冲突解决办法
HashMap 底层采用链表法来解决冲突。即使负载因子和散列函数设计得再合理,也免不了会出现拉链过长的情况,一旦出现拉链过长,则会严重影响 HashMap 的性能。
于是在 JDK 1.8 版本中,为了对 HashMap 做进一步优化,我们引入了红黑树。当链表长度太长(默认超过 8 )时,链表就转换为红黑树。我们可以使用红黑树快速增删改查的特定,提升 HashMap 的性能。当红黑树节点少于 8 时,又会将红黑树转化为链表。
4. 散列函数
散列函数的设计并不复杂,追求的是简单高效、分布均匀。
以下是 java 的 hash 函数:
1 | int hash(Object key) { |
Python dictobject
python 字典
1. 初始大小
dict 的初始大小是 8 个存储桶。
其中桶是一种特殊的数据结构:
1 | typedef struct { |
2. 装载因子和动态扩容
在 CPython 中,装载因子的阈值通常是 2/3。当字典中的键值对数量超过当前存储桶的 2/3 时,就会触发动态扩容。
下面是动态扩容的大致步骤:
- 当字典的装载因子超过阈值时,触发动态扩容操作。
- 计算新的存储桶数量,通常是当前存储桶数量的两倍。
- 分配一个新的存储桶数组,并进行初始化。
- 遍历原存储桶数组中的键值对。
- 对于每个键值对,根据键的哈希值和新的存储桶数量,计算键在新存储桶数组中的位置。
- 将键值对插入新的存储桶数组中的对应位置。
- 释放原存储桶数组的内存。
- 更新字典的元数据,包括存储桶数量和已使用的存储桶数量。
这样的动态扩容操作确保了字典可以适应更多的键值对,并且保持较高的查找效率。在扩容期间,字典仍然保持可用,但插入操作可能会稍微慢一些。
请注意,动态扩容过程中并不会同时维护两个哈希表,而是在新的存储桶数组中重新哈希所有的键值对。这样确保了字典的一致性和正确性。
3. 散列冲突解决办法
CPython使用开放寻址法来解决哈希冲突,具体而言是线性探测法。
当发生哈希冲突时,CPython会按照以下步骤解决冲突:
- 根据键的哈希值计算存储桶的初始位置。
- 如果该位置的存储桶为空(未被占用),则将键值对插入该位置。
- 如果该位置的存储桶已经被占用,则继续线性探测,即依次检查下一个存储桶,直到找到一个空槽或者完全遍历整个存储桶数组。
- 当找到一个空槽时,将键值对插入该位置。
- 如果遍历整个存储桶数组都没有找到空槽,即所有的存储桶都被占用了,那么会触发动态扩容,重新分配更大的存储桶数组,并重新哈希键值对。
通过线性探测,CPython尝试在哈希冲突的情况下找到下一个可用的存储桶。这样,具有相同哈希值的键值对可以在存储桶数组中找到不同的位置。
需要注意的是,线性探测法可能会导致聚集(clustering)现象,即连续的键值对被插入到相邻的存储桶中,造成查找和插入操作的性能下降。为了缓解这个问题,CPython还使用了二次探测(quadratic probing)和双重散列(double hashing)等技术来处理冲突,以提高字典的性能。
总结起来,CPython中字典解决哈希冲突的方法是使用开放定址法,具体而言是线性探测法。在冲突发生时,它会线性探测存储桶数组,直到找到一个空槽或者触发动态扩容操作。这样保证了具有相同哈希值的键值对能够被正确插入到字典中。
4. 散列函数
自从CPython 3.4版本开始,它使用了一种称为”SipHash”的哈希算法。SipHash是一种快速且安全的哈希算法,适用于哈希表等数据结构。它被设计为具有较低的碰撞概率和高度的安全性。
CPython使用SipHash算法计算散列值,以保证字典的安全性和效率。这是CPython中哈希函数的默认实现。