Redis 常用的数据类型剖析
Redis 数据库介绍
Redis 是一种键值(Key-Value)、基于内存的非关型数据库、读写性能非常好。
Redis 中,键的数据类型是字符串,常用的值的数据类型有:字符串、列表、列表、集合、有序集合
列表(list)
列表这种数据类型支持存储一组数据。这种数据类型对应两种实现方法:
- 压缩列表(ziplist)
- 双向循环链表(circle chain)
当列表中存储的数据量比较小的时候,列表可以采用压缩列表的方式实现:
- 列表中保存的单个数据(有可能是字符串类型)小于 64 字节;
- 列表中的数据少于 512 个;
如何理解这种压缩列表?
压缩列表这种存储结构,一方面比较节省内存,另一方面可以支持不同类型数据结构的存储。而且,因为数据存储在一片连续的内存空间,通过键来获取值为列表类型的数据,读取的效率也非常高。
源码:https://github.com/redis/redis/blob/3b462ce566e577ffcb35822a0a2372f691326cd4/src/adlist.h
1 | // 以下是C语言代码,因为Redis是用C语言实现的。 |
字典
字典类型用来存储一组数据对。可以理解为 key-value-field
字典类型也有两种实现方法:
- 压缩列表(ziplist)
- 散列表
当存储的数据量比较小的情况下,Redis 才使用压缩列表来实现字典类型:
- 字典中保存的键和值的大小都要小于 64 字节;
- 字典中的键值对的个数都要小于 512 个;
当存储的数据不满足以上条件时,Redis 就使用散列表来实现字典类型:Redis 使用 MurmmurHash2 这种运行速度快、随机性好的哈希算法作为哈希函数。对于哈希冲突问题,Redis 使用 链表法来解决。此外 Redis 还支持散列表的动态扩容、缩容:
- 当数据动态增加之后,散列表的装载因子会不停地变大。为了避免散列表性能的下降,当装载因子大于 1 的时候,Redis 会触发扩容,将散列表扩大为原来大小的 2 倍左右。
- 当数据动态减少时,为了节约内存,当装载因子小于 1.0 的时候,Redis 就会触发缩容,缩小为字典中数据个数的大约 2 倍大小。
为了避免缩容与扩容的大量的数据搬移和哈希值的重新计算的耗时,Redis 使用的是渐进式缩容扩容策略,将数据的搬移分批进行,避免大量数据一次性搬移导致的服务停顿。
集合
集合这种数据类型用来存储一组不重复的数据。**这种数据类型也有两种实现方法: **
- 一种是基于有序数组
- 另一种是基于散列表
有序数组使用的限制:
- 存储的数据都是整数
- 存储的数据元素个数不超过 512 个
当不同同时满足这两个条件的时候,Redis 就使用散列表来存储集合中的数据。
有序集合
它用来存储一组数据,并且每个数据会附带一个得分。
和 Redis 的其他类型的数据一样,有序集合也并不仅仅只有跳表这一种实现方式,当数据量比较小的时候,Redis 会使用压缩列表来实现有序集合:
- 所有的数据大小都要小于 64 字节;
- 元素个数都要小于 128 个;
数据持久化
Redis 虽然是内存数据库,但是也支持数据落盘,其中有两种是持久化方式:aof && rdb;
如何将数据结构持久化到硬盘,主要有两种思路:
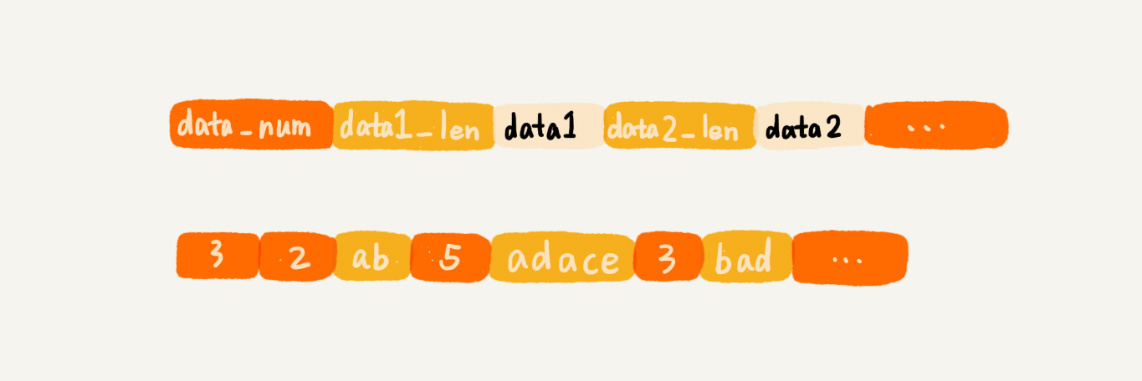
第一种是清除原有的存储结构,只将数据存储到磁盘中。当我们需要从磁盘还原数据到内存的时候,再重新将数据组织成原来的数据结构。实际上,Redis 采用的就是这种持久化思想。
第二种方式就是保留原来的存储格式,将数据按照原有的格式存储在磁盘中。例如散列表:可以将散列表的大小、每个数据被散列到的槽的编号等信息,都保存在磁盘中。有了这些信息,我们从磁盘中将数据还原到内存中的时候,就可以避免重新计算哈希值。
总结:
redis 的数据类型可以由多种数据结构实现,主要是出于时间和空间的考虑。
当数据量较小时,采用连续空间的数据结构,例如压缩数组和有序数组,可以提升访问效率
当数据量较大时,采用采用链表结构,节省内存,同时当需要保证速度的时候,就可以使用散列表来实现。